Définitions des Hôtes
Cette page explique les différentes stratégies pour récupérer les fichiers à télécharger sur un site donné.
Des compétences en informatique sont un sérieux atout ici.
Une bonne connaissance de XML, XPath et des expressions régulières facilitera la compréhension.
Fichier Hosts.xml
Les définitions des hôtes sont centralisées dans un fichier XML.
L’emplacement de ce fichier peut être changé dans les préférences de l’extension.
Le fichier XML contient une structure hiérarchique qui ressemble à…
<?xml version="1.0" encoding="UTF-8"?>
<root>
<host id="host 1">
<domain>...</domain>
<path-pattern>...</path-pattern>
<link-search-pattern>...</link-search-pattern>
</host>
<host id="host 2">
<domain>...</domain>
<path-pattern>...</path-pattern>
<link-search-pattern>...</link-search-pattern>
</host>
</root>
Chaque hôte est associé à un item.
Pour ajouter un nouvel hôte, il suffit donc de rajouter un item dans ce fichier.
Il est même possible de définir plusieurs items pour un même hôte. Par exemple…
<?xml version="1.0" encoding="UTF-8"?>
<root>
<host id="instagram-pics">
<domain>...</domain>
<path-pattern>...</path-pattern>
<link-search-pattern>...</link-search-pattern>
</host>
<host id="instagram-vids">
<domain>...</domain>
<path-pattern>...</path-pattern>
<link-search-pattern>...</link-search-pattern>
</host>
</root>
Il est recommandé de leur donner des ID différents.
Cet identifiant sert en cas d’erreur à corriger ou en cas d’évolution.
Principe Général
Tout part de l’analyse du code source de la page web. Celle-ci se fait en 3 grandes étapes :
1. Où doit-on rechercher les liens des fichiers à télécharger ?
- Sur la page actuelle ?
- Ou sur une autre page, référencée depuis l’actuelle ?
C’est ce que les propriétés domain et path-pattern définissent, à savoir quelle(s) page(s) analyser pour collecter les liens de téléchargement.
2. Une fois ces pages connues, la recherche des liens peut commencer. Ce sont les propriétés link-search-pattern et link-attribute qui déterminent le comportement, et en particulier link-search-pattern :
- Il peut rechercher les liens de manière textuelle (stratégies
expreg,replace,self). - Il peut aussi rechercher des éléments dans le DOM de la page web (stratégies
ID,class,XPath,CSS query). Dans ce cas, il faut compléter la définition pour préciser l’attribut HTML à considérer, à l’aide de la propriété link-attribute.
3. Quand on a défini comment les liens de téléchargement doivent être collectés, alors on peut préciser la politique de nommage : quels noms donner aux fichiers téléchargés ? Par défaut, ce nom est déduit de l’URL, mais pour les stratégies basées sur une approche DOM, le nom peut être récupéré depuis un autre attribut HTML. Ainsi, si l’on se sert de la stratégie XPath pour repérer les éléments HTML img, alors le lien de téléchargement est pris dans l’attribut src, tandis que le nom du fichier peut être pioché dans l’attribut alt ou title.
4. Enfin, entre chacune de ces étapes peuvent s’intercaler des intercepteurs, qui peuvent procéder à des réécritures ou des remplacements. Ainsi, un intercepteur peut…
- … modifier où l’on va rechercher des liens.
- … corriger des liens de téléchargement.
- … retravailler le nom des fichiers.
Créer un item dans le catalogue revient à spécifier ces étapes, qui sont toutes séquentielles et qui s’étendent depuis l’analyse de la page web visitée jusqu’au téléchargement de fichiers.
C’est ce que synthétise le schéma ci-dessous.
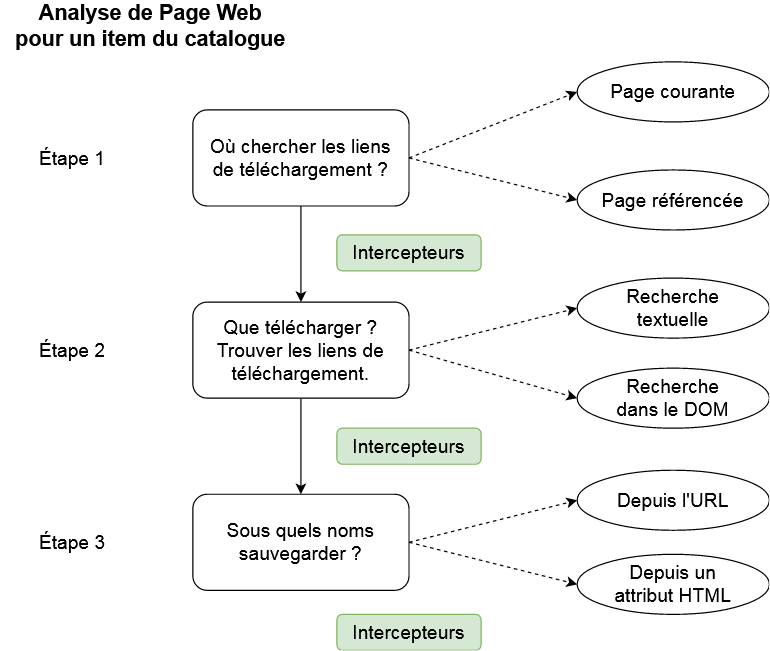
A chaque analyse de page, l’intégralité des règles du catalogue suivent cette séquence et enrichissent la liste des liens à récupérer. Cela peut potentiellement être utilisé pour n’importe quel type de fichiers (images, médias). Le catalogue ressemble au fichier XML illustré dans la section précédente, alors que les propriétés qu’il accepte sont présentées plus en détail dans les paragraphes suivants.
Domaine
Les Domaines Simples
Le domaine concerne celui des liens à découvrir et explorer.
Par exemple, si l’on souhaite trouver tous les liens qui pointent vers http://toto.net,
alors le nom de domaine est toto.net.
<domain>toto.net</domain>
Lorsque vous définissez un domaine, HG ++ considérera tous les préfixes http, https, www., ainsi que les sous-domaines. La valeur d’un domaine est un simple texte. Ce n’est pas une expression régulière.
Règle Particulière (indépendante du domaine)
Si la règle s’applique à de nombreux sites web, alors il est possible d’utiliser la
valeur _$ANY$_.
<domain>_$ANY$_</domain>
Plusieurs sites proposent une galerie basée sur
Coppermine. La règle associée ne spécifie donc pas de
domaine particulier. Elle s’applique sur tous les sites. Lors de l’analyse d’une page, la
valeur _$ANY$_ signfie que l’on utilise le nom d’hôte de la page courante.
Si l’on garde l’exemple de Coppermine, imaginons qu’une telle galerie soit hébergée sur toto.net. Lors d’une visite sur ce site, IHG ++ trouverait tous les médias hébergés sur toto.net utilisant la règle Coppermine. Cependant, si quelque part dans la page apparaît un lien vers une autre galerie Coppermine (hébergée par exemple sur un-autre-site.com), alors ce lien ne sera pas pris en compte.
La valeur _$ANY$_ s’applique potentiellement à n’importe quel domaine.
Mais dés qu’elle est utilisée sur une page donnée, alors seul le domaine courant est considéré.
Expressions Régulières pour un Domaine
Il est possible d’utiliser une expression régulière pour un domaine.
Il faut alors utiliser la balise domain-pattern.
<domain-pattern>toto\d+\.net</domain-pattern>
<!--
Cet exemple accepte n'importe quelle déclinaison du domaine qui se termine par un entier :
toto1, toto2, toto24, toto528, etc.
-->
Tout comme pour un domaine, les préfixes http, https,
www., ainsi que les sous-domaines, sont gérés automatiquement.
Contrairement à la constante _$ANY$_, cette règle acceptera n’importe quel lien
dont le domaine correspond à l’expression régulière, et quelle que soit la page courante.
Modèle de Chemin
Le modèle de chemin (path pattern) permet d’identifier quoi explorer sur un domaine donné.
Deux types de valeurs sont autorisées.
Trouver des Liens à Explorer
Dans le premier cas, il s’agît de trouver des pages à visiter depuis celle qui est ouverte. Le modèle de chemin doit alors être une expression régulière. Quand vous visitez une page web et que vous activez Host Grabber, celui-ci analyse le code source de la page. Toutes les parties de texte qui correspondent au domaine et au modèle de chemin vont être mises de côté pour une analyse détaillée.
Ainsi, si vous visitez un forum avec des images, le modèle d’URL permet de trouver les liens qui mènent aux sites qui hébergent ces images.
Ce guide n’a pas pour ambition d’expliquer ce qu’est une expression régulière.
Cependant, voici un exemple pour trouver les pages hébergées par mon-hebergeur.
<path-pattern>.+\.jpg</path-pattern>
Il y a quelques règles à connaître pour la définition de cette propriété.
- Elle ne peut pas commencer par
/. - Elle ne peut pas commencer par
^. - Elle ne peut pas finir par
$. - Le symbole
.sera remplacé par[^<>"]. - Pour obtenir le symbole
., il faut écrire˙. - L’entité HTML
<doit être écrite sous la forme<. - L’entité HTML
>doit être écrite sous la forme>. - L’entité HTML
&doit être écrite sous la forme&.
Explorer la Page Actuelle Uniquement
L’utilisation d’une expression régulière est réservée à la découverte
de page à explorer. Mais parfois, seul le code source de la page actuelle
devrait être exploré. La valeur _$CURRENT$_ est alors la solution.
Elle permet d’appliquer les modèles de recherche (XPath, replace, etc) sur la page courante.
Modèle de Recherche des Liens
Le modèle d’URL permet de trouver quoi explorer.
The modèle de recherche (search pattern) permet de trouver les liens de téléchargement parmi ce qu’il faut explorer.
Plusieurs stratégies sont disponibles. Certaines sont gourmandes en ressources, d’autres non. Elles sont détaillées ci-dessous.
SELF
Il s’agît de la stratégie la plus simple.
Ici, le modèle d’URL détermine quoi télécharger.
Syntaxe de Référence : self (insensible à la casse)
Exemple : liens directs vers des images.
<domain>toto.com</domain>
<path-pattern>.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>SELF</link-search-pattern>
Le modèle d’URL permet ici de trouver tous les fichiers JPG, PNG et GIF dans la page.
Et self implique de télécharger directement ces éléments, sans plus d’analyse.
Replace
Il s’agît d’une stratégie économe.
Elle repose sur l’idée que le lien de téléchargement peut être déduit du modèle d’URL.
Syntaxe de Référence : replace: 'expression régulière', 'remplacement' (insensible à la casse)
Exemple : galerie d’images avec miniatures.
<domain>toto.com</domain>
<path-pattern>.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>replace: 'tn_', ''</link-search-pattern>
Ce modèle d’URL identifie des images qui pourraient être des miniatures.
Et le modèle de recherche permet de remplacer certains segments de l’URL.
Notez que l’on peut aussi utiliser une expression régulière pour la recherche.
<domain>toto.com</domain>
<path-pattern>.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>replace: 'images/mini/([^/]+)/tn_(.*)', 'images/originales/$1/$2'</link-search-pattern>
Avec ce modèle de recherche, une miniature située à l’adresse http://toto.com/images/mini/novembre-2017/tn_01.jpg
serait résolue en http://toto.com/images/originales/novembre-2017/01.jpg. $1 et $2 sont des références vers des
groupes de capture (les segments entre parenthèses dans l’expression régulière).
ID
ID est une stratégie gourmande.
Elle implique de télécharger les pages pointées par les liens trouvés lors de l’exploration.
A moins que le modèle de chemin ne pointe vers la page actuelle.
Par exemple, si le modèle d’URL a permis d’identifier un lien vers mon-hebergeur, alors Host Grabber va le suivre, télécharger la page et l’analyser pour en extraire les médias à téléchager. Dans ce cas précis, les liens de téléchargement sont trouvés en cherchant un élément HTML dont l’ID est spécifié dans le modèle de recherche. Pour rappel, un ID est unique au sein d’une page web. Deux éléments ne peuvent pas avoir le même.
Syntaxe de Référence : ID: l'id html (insensible à la casse)
Exemple : plusieurs hébergeurs d’images.
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>ID: image</link-search-pattern>
En supposant que ce modèle d’URL mène à des liens du genre http://mon-hebergeur.com/view.php?01.jpg,
Host Grabber les suivraient tous, téléchargerait les pages cibles et les analyserait. Chaque page ayant un
élément HTML avec l’ID spécifié donnerait lieu à un téléchargement.
Class
Class est une stratégie gourmande.
Elle implique de télécharger les pages pointées par les liens trouvés lors de l’exploration.
A moins que le modèle de chemin ne pointe vers la page actuelle.
Par exemple, si le modèle d’URL a permis d’identifier un lien vers mon-hebergeur, alors Host Grabber va le suivre, télécharger la page et l’analyser pour en extraire les médias à téléchager. Dans ce cas précis, les liens de téléchargement sont trouvés en cherchant les éléments img dont la classe est spécifiée dans le modèle de recherche.
Syntaxe de Référence : Class: la classe html (insensible à la casse)
Exemple : plusieurs hébergeurs d’images.
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>Class: image</link-search-pattern>
En supposant que ce modèle d’URL mène à des liens du genre http://mon-hebergeur.com/view.php?01.jpg,
Host Grabber les suivraient tous, téléchargerait les pages cibles et les analyserait. Chaque page ayant des
éléments HTML avec la classe spécifiée donnerait lieu à des téléchargements.
XPath
XPath est une stratégie gourmande.
Elle implique de télécharger les pages pointées par les liens trouvés lors de l’exploration.
A moins que le modèle de chemin ne pointe vers la page actuelle.
Par exemple, si le modèle d’URL a permis d’identifier un lien vers mon-hebergeur, alors Host Grabber va le suivre, télécharger la page et l’analyser pour en extraire les médias à téléchager. Dans ce cas précis, les liens de téléchargement sont trouvés en cherchant un élément ou un attribut HTML grâce à une expression XPath.
Syntaxe de Référence : XPath: une expression XPath (insensible à la casse)
Exemple : plusieurs hébergeurs d’images.
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>XPath: //div[@class=image-container]/img</link-search-pattern>
En supposant que ce modèle d’URL mène à des liens du genre http://mon-hebergeur.com/view.php?01.jpg,
Host Grabber les suivraient tous, téléchargerait les pages cibles et les analyserait. Les liens de téléchargement
seraient trouvés en cherchant une balise img, située sous une balise div ayant image-container comme classe.
Notez que les stratégies Class et ID sont des raccourcis pour la stratégie XPath.
Expreg
Expreg est une stratégie gourmande.
Elle implique de télécharger les pages pointées par les liens trouvés lors de l’exploration.
A moins que le modèle de chemin ne pointe vers la page actuelle.
Par exemple, si le modèle d’URL a permis d’identifier un lien vers mon-hebergeur, alors Host Grabber va le suivre, télécharger la page et l’analyser pour en extraire les médias à téléchager. Dans ce cas précis, les liens de téléchargement sont trouvés grâce à une expression régulière.
Syntaxe de Référence : Expreg: a regular expression (insensible à la casse)
Exemple : plusieurs hébergeurs d’images.
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern><![CDATA[expreg: <meta property="og:image"\s+content="([^"]+)"]]></link-search-pattern>
En supposant que ce modèle d’URL mène à des liens du genre http://mon-hebergeur.com/view.php?01.jpg,
Host Grabber les suivraient tous, téléchargerait les pages cibles et les analyserait. Les liens de téléchargement
seraient trouvés grâce à une expression régulière. Si un groupe de capture est présent, son contenu est résolu
en tant que lien de téléchargement. Autrement, c’est la correspondance toute entière qui est prise. Voici un exemple
pour illustrer ce cas (aucune parenthèse dans l’expression régulière).
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern><![CDATA[expreg: http://.*/grandes/.*\.jpg]]></link-search-pattern>
Ici, seules les images localisées dans le répertoire grandes seront téléchargées.
Vous avez dû remarquer l’utilisation de sections CDATA dans ces derniers exemples.
Elles sont utilisées pour prévenir des erreurs au niveau XML.
CSS Query
CSS Query est une stratégie gourmande.
Elle implique de télécharger les pages pointées par les liens trouvés lors de l’exploration.
A moins que le modèle de chemin ne pointe vers la page actuelle.
Par exemple, si le modèle d’URL a permis d’identifier un lien vers mon-hebergeur, alors Host Grabber va le suivre, télécharger la page et l’analyser pour en extraire les médias à téléchager. Dans ce cas précis, les liens de téléchargement sont trouvés en cherchant un élément img grâce à une requête CSS.
Syntaxe de Référence : CSS query: une requête CSS (insensible à la casse)
Exemple : plusieurs hébergeurs d’images.
<domain>mon-hebergeur.com</domain>
<path-pattern>view\.php\?.*\.(jpg|png|gif)</path-pattern>
<link-search-pattern>CSS query: div.col-md-12 img</link-search-pattern>
En supposant que ce modèle d’URL mène à des liens du genre http://mon-hebergeur.com/view.php?01.jpg,
Host Grabber les suivraient tous, téléchargerait les pages cibles et les analyserait. Les liens de téléchargement
seraient trouvés en cherchant une balise img, située sous une balise div ayant col-md-12 comme classe.
Pour utiliser le sélecteur > dans une requête CSS, il faut le remplacer par >.
Exemple : div.col-md-12 > img sera interprété comme div.col-md-12 > img
Page Actuelle
Si le modèle de chemin a pour valeur _$CURRENT$_, et que la page actuellement visitée appartient
au domaine défini, alors c’est la page actuelle qui sera explorée directement. Autrement dit, on n’extrait
pas de lien à explorer de la page, et on applique le modèle de recherche directement.
Ainsi, dans cet exemple…
<domain>toto.com</domain>
<path-pattern>_$CURRENT$_</path-pattern>
<link-search-pattern>CLASS: img</link-search-pattern>
… si l’on visite une page du site toto.com, alors on va chercher toutes les images dont la classe CSS est img. Ce mécanisme fonctionne avec toutes les stratégies des modèles de recherche.
Attribut pour les liens
Comme son nom l’indique, le modèle de recherche de liens permet de trouver des liens.
Quand cette recherche s’appuie sur l’analyse du DOM, alors la propriété doit désigner un élément HTML, ce qui implique qu’il faut préciser un attribut HTML en plus. C’est l’objet de cette propriété.
<domain>toto.com</domain>
<path-pattern>_$CURRENT$_</path-pattern>
<link-search-pattern>CLASS: img</link-search-pattern>
<link-attribute>src</link-attribute>
Cette balise est optionnelle et n’a de sens que pour les stratégies ID, class, XPath et CSS query. Elle permet d’indiquer le nom de l’attribut HTML pour extraire le lien de téléchargement. Sa valeur par défaut est src (ce qui explique pourquoi elle est optionnelle).
Attribut pour les noms de fichiers
Cette balise est optionnelle et peut être utilisée à deux fins.
Pour les stratégies ID, class, XPath et CSS query, elle permet d’indiquer le nom de l’attribut HTML pour extraire le nom du fichier. Puisque ces stratégies ciblent des éléments HTML, on peut piocher dans un de ses attributs. Par exemple, plusieurs hébergeurs d’images génèrent des noms aléatoires pour les liens, et conservent le nom d’origine dans les attributs alt ou title. Dans un tel cas, c’est donc le nom d’un de ces attributs que l’on mettrait dans la balise. A noter qu’en cas d’absence, le nom sera déduit depuis l’URL.
<domain>toto.com</domain>
<path-pattern>_$CURRENT$_</path-pattern>
<link-search-pattern>CLASS: img</link-search-pattern>
<link-attribute>src</link-attribute>
<file-name-attribute>alt</file-name-attribute>
Elle peut aussi être utilisée en tant que séparateur, pour ajouter des intercepteurs sur le nom du fichier (y compris pour les stratégies textuelles comme self, expreg et replace). Quand cette propriété est vide, alors le nom par défaut (déduit de l’URL) est utilisé.
<domain>toto.com</domain>
<path-pattern>_$CURRENT$_</path-pattern>
<link-search-pattern>CLASS: img</link-search-pattern>
<link-attribute>src</link-attribute>
<file-name-attribute></file-name-attribute>
<interceptor>replace: '\.jpeg', '.jpg'</interceptor>
Intercepteurs
HG ++ explore des pages web afin de découvrir des liens de téléchargement. Parfois, ces liens ne sont exactement ceux que l’on souhaiterait. Il peut aussi arriver que certains hébergeurs changent de nom de domaine. C’est assez rare, mais c’est pourtant ce qui est arrivé à PixHost. Jusqu’à fin 2017, ce site utilisait le domaine pixhost.org. Depuis 2018, il a perdu ce nom de domaine et a dû basculer sur pixhost.to.
Host Grabber ++ propose un mécanisme de redirection qui peut être utilisé dans les dictionnaires. On peut s’en servir pour, par exemple, rediriger depuis un ancien domaine vers un plus récent. Ou bien encore pour cibler un élément que l’exploration n’a pas pu atteindre directement.
Voici un exemple…
Quand un lien est trouvé et qui pointe vers pixhost.org, l’extension ira sur la bonne
page mais sur le domaine pixhost.to.
<host id="pixhost-org">
<domain>pixhost.org</domain
<path-pattern>show/.+</path-pattern>
<interceptor>replace: '\.org/', '.to/'</interceptor>
<link-search-pattern>ID: image</link-search-pattern>
</host>
L’intercepteur remplace une partie de l’URL par autre chose.
La syntaxe est la même que pour la directive de remplacement dans les modèles de recherche.
Un intercepteur peut apparaître en plusieurs endroits.
- Après une balise path-pattern : le remplacement se fera sur les liens trouvés dans l’onglet d’origine et qui sont à explorer.
- Après une balise link-search-pattern : le remplacement se fera sur les liens trouvés durant l’exploration.
- Après une balise file-name-attribute : le remplacement se fera sur le nom du fichier (quel que soit l’endroit où il a été trouvé).
Il est aussi possible de définir plusieurs intercepteurs.
<host id="pixhost-org">
<domain>pixhost.org</domain>
<path-pattern>show/.+</path-pattern>
<!-- Explorer une autre page que celle découverte dans l'onglet courant. -->
<interceptor>replace: '\.org/', '.to/'</interceptor>
<interceptor>replace: 'show/', 'view/'</interceptor>
<link-search-pattern>ID: image</link-search-pattern>
<!-- L'explotation a découvert des miniatures. Redirection vers des images plus grandes. -->
<interceptor>replace: '_tn\.jpg', '_big.jpg'</interceptor>
</host>
Parce que l’exploration pourrait être sans fin, des limites ont été posées. Il est possible que certaines pages ou sites web ne soient pas exploitables avec une combinaison d’intercepteurs et de modèle de recherche. Toutefois, cette solution offre suffisamment de flexibilité pour les cas complexes les plus fréquents.
Liens Relatifs
Les liens relatifs sont résolus par rapport à la page où ils ont été trouvés.
Ils sont donc correctement gérés.
Résolution des Problèmes
Tout semble correct, et pourtant cela ne marche pas.
Même si c’est hautement improbable, il est possible que vous ayez inséré des caractères invisibles dans le catalogue. Ceci est déjà arrivé. Identifiez l’entrée du catalogue, retapez-la depuis zéro, sans copier-coller, puis essayez à nouveau.